Het beste resultaat uit het inlezen van een cv halen
Het inlezen van een cv is niet te vergelijken met het importeren van data waar velden altijd in duidelijke structuur staan en het dus altijd duidelijk is welke waarde in welk veld moet worden opgeslagen en welke gegevens bij elkaar horen.
Om een zo’n goed mogelijk resultaat te halen hebben we hier een uitleg gemaakt over hoe het beste resultaat behaald kan worden.
In een notendop
Als er in het cv binnen een bepaalde sectie gegevens staan die niet herkent kunnen worden zal dit mogelijk wel worden gebruikt om inhoud te herkennen waardoor de kwaliteit van het inlezen van die sectie in zijn geheel kan afnemen. Onderstaand is te vinden welke velden wel herkend kunnen worden.
Als u een PDF inleest en u vindt het resultaat na het inlezen niet goed genoeg kunt u het proberen op te slaan als een Rich Text Format (.rtf) bestand. In het gratis programma Adobe Acrobat Reader kunt u het bestand opslaan als een RTF bestand. Raadpleeg de handleiding van Adobe Acrobat (of een andere PDF reader hoe u dit kunt doen op uw systeem).
Als u een Word document inleest en u vindt het resultaat na het inlezen niet goed genoeg kunt u het proberen op te slaan als een Rich Text Format (.rtf) bestand. In Microsoft Office Word kunt u het bestand opslaan als een RTF bestand. Raadpleeg de handleiding van Microsoft Office Word (of uw tekstverwerker hoe u dit kunt doen op uw systeem).
Indien bovenstaande allemaal niet werkt is het handmatig invoeren van de gegevens wellicht de meest effectieve oplossing.
Herkenning
Alle cv’s worden ingelezen via de industrie standaard in cv-herkenning: Textkernel. Per sectie wordt er gezocht naar een aantal velden probeert dit programma alles zo goed mogelijk te herkennen. Dat is een pittige klus, zelfs voor Artificial Intelligence (AI), want geen cv is vergelijkbaar als het gaat om inhoud of structuur.
Er zijn de volgende onderdelen waarnaar gezocht wordt:
- Personalia
- Opleidingen, cursussen, certificaten
- Werkervaring, nevenactiviteiten
- Gesproken talen
- Skills
- Hobbies
Voor een zo nauwkeurig mogelijk resultaat is het nuttig om velden die niet genoemd worden weg te halen. Als er in het cv binnen een bepaalde sectie gegevens staan die niet herkent kunnen worden zal dit mogelijk wel worden gebruikt om inhoud te herkennen waardoor de kwaliteit van het inlezen van die sectie in zijn geheel kan afnemen. Onderstaand is te vinden welke velden wel herkend kunnen worden.
Het vermelden van jaartallen of periodes in de omschrijving van een ervaring wordt afgeraden omdat deze vaak herkend wordt als nieuwe werkervaring.
Als het een project is geweest, en uw organisatie maakt gebruik van de mogelijkheid om projecten aan te duiden in de werkervaring, raden we u aan om een project net zo vorm te geven als een gewone werkervaring.
U kunt dan later met een klik aangeven welke werkervaring een project is.
Algemene indeling van de tekst
Om aan te geven dat een stuk tekst bij elkaar hoort kunt u het beste gebruik maken van groepen gegevens die bij elkaar horen. In onderstaand voorbeeld staan de werkgever, de functietitel en de start en/of einddatum van de werkervaring elk op een eigen regel.
Als er een omschrijving is adviseren wij om voor en na de hele tekst een witregel te laten vallen en daartussen geen witregels te gebruiken:

slechts om beter aan te geven dat er blokken tekst zijn die bij elkaar horen.
Onderdelen welke niet benoemd zijn kunnen niet herkent worden en zullen dus handmatig overgezet moeten worden.
Personalia
De software gaat op zoek naar de onderstaande velden:
- Voornaam
- Achternaam (incl. tussenvoegsel(s))
- Titel
- Nationaliteit
- Geboorte datum
- Geslacht (m/v/o)
- Huwelijkse staat
- Straat
- Huisnummer
- Postcode
- Stad
- Land
- Vaste nummer
- Mobiele nummer
Opleidingen, cursussen, certificaten
Per opleiding, cursus of certificaat worden gevonden resultaten bij elkaar gestopt. In EazyCV kun je deze dan verplaatsen van het een naar het ander.
- Opleidingsniveau
- Opleidingsnaam
- Opleidingsinstituut
- Start datum
- Eind datum
Werkervaring, nevenactiviteiten
Per werkervaring of nevenactiviteit wordt gescand op de volgende waarden:
- Functietitel
- Werkgever
- Start datum
- Eind datum
- Omschrijving van de werkzaamheden
Gebruik in werkzaamheden geen dubbele punt (:) voorafgaande aan een opsomming. De tekstherkenning herkent dat niet goed en zal de tekst rondom deze dubbele punt niet overnemen.
Nevenactiviteiten worden meestal genegeerd ondanks dat je ze later wel kunt invoeren. Als ze belangrijk zijn kun je ze het beste onder werkervaring indelen en later verplaatsen naar nevenactiviteiten (indien je organisatie daar ruimte voor biedt).
Gesproken talen
Aan talen worden twee zaken gekoppeld:
- Taal
- Niveau
Skills
Voor skills gaat de tekstherkenning door heel het cv heen om te kijken waar je goed in bent. Als je een specifiek lijstje maakt met je eigen skills worden die ook meegenomen.
Hobbies, sporten
Maak er gewoon een lijstje van dan herkent de software automatisch je hobbies & sporten
Opmaak
Sommige bestanden hebben een ontzettend mooie, maar voor een computer moeilijk begrijpbare opmaak. Het beste kun je dan zorgen dat ze in RTF (rich text format of .rtf) geupload worden.
Voor PDF hangt het af van je PDF Reader. Uitgaande van het gratis Adobe Acrobat Reader zijn de stappen als volgt:
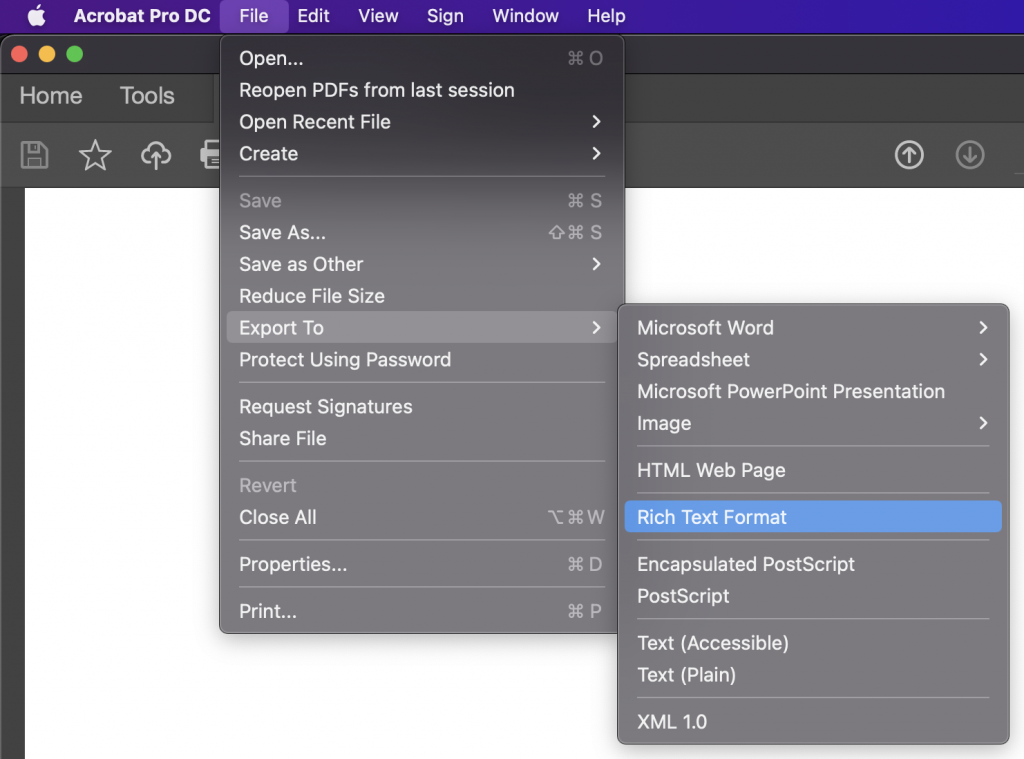
Indien je Microsoft Office Word gebruikt zijn de stappen als volgt:
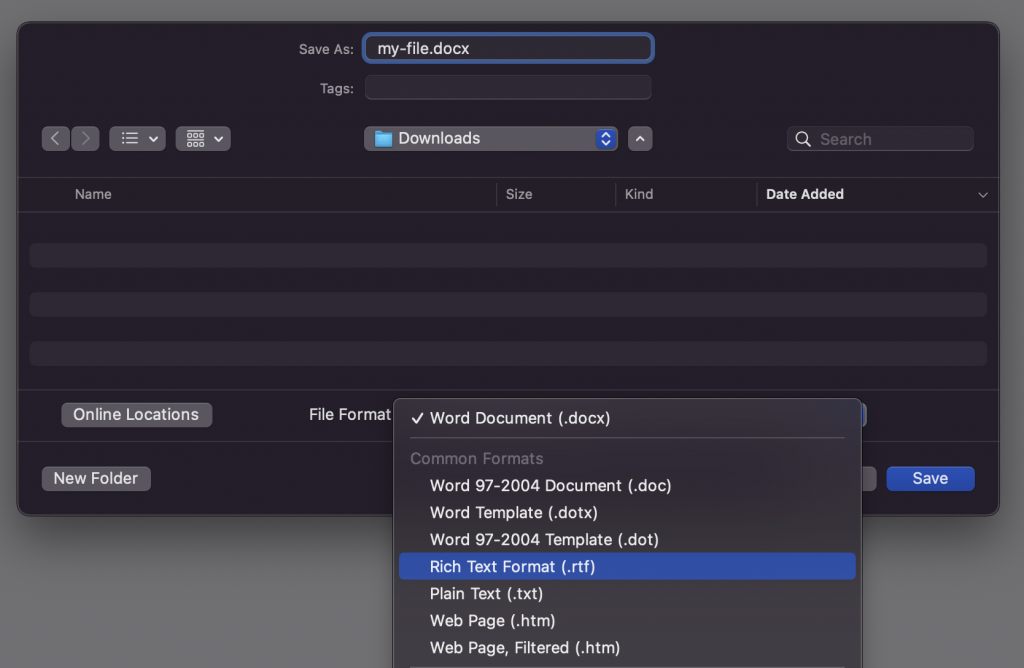
Indien u een andere applicatie gebruikt moet u de handleiding van de software leverancier er op na slaan.
Sjabloon
Het beste resultaat is te behalen door een cv op of om te bouwen zodat het lijkt op dit sjabloon. Hiermee behaal je over het algemeen gemakkelijk 85% accurate overdracht van gegevens.
Bovenstaand is een algemeen sjabloon. We kunnen een sjabloon maken dat beter past bij jullie organisatie. Vraag je key-user of zij dit bij EazyCV willen aanvragen.
Was this helpful?
3 / 0